为什么不直接用 JDBC,而要 ORM 框架
直接使用 JDBC 操作比较繁琐:
-
先创建 connection 连接数据库
-
创建 statement 对象
-
通过 statement 对象执行 sql 语句,得到 resultSet
-
遍历 resultSet,获取结果,并将记录手动转为 JavaBean
-
关闭 resultSet、statement 、connection,释放资源防止泄露
对于每一个 sql 来说,都需要重复执行上面的命令,重复代码非常多,且遍历结果集记录转换成 JavaBean的也很繁琐,简而言之,很多搬砖的无脑操作需要重复写。
而且生成上的项目还需要用连接池,不能用完了之后直接释放连接,重复建连开销大。
基于上面这些点,一个 ORM 框架就能解放我们的双手,把我们从重复无脑的搬砖行为中解脱出来,且简化代码,还提供缓存、连接管理、事务等操作。
提升我们的开发效率和提高系统的可维护性。
Hibernate
是一款完整形态的 ORM 框架,可以从纯面向对象的角度来操作数据库。
它不仅能帮助我们完成对象模型和数据库关系模型的映射,还能帮助我们屏蔽不同数据库不同 SQL 的差异,简单来说我们用 Hibernate 提供的 API 就能完成大部分 SQL 操作,不需要我们编写 SQL,Hibernate 会帮助我们生成 SQL。
且也提供了 HQL(Hibernate Query Language),面向对象的查询语句,和 SQL 类似但是不太相同,最终 HQL 会被转化成 SQL 执行
还提供了 Criteria 接口,也是一样,是一套面向对象的 API,一些复杂的 SQL 可以利用 Criteria 来实现,非常灵活。
总而言之, Hibernate 通过面向对象的思维让你操作数据库,屏蔽不同数据库的差异,它会根据底层不同数据库转化成对应的 SQL。
缺点就是屏蔽的太多了,例如因为自动生成 SQL,所以我们无法控制具体生成的语句,你无法直接决定它走哪个的索引,且又经过了一层转化 SQL 的操作,所以性能也会有所影响。
简而言之,Hibernate 很好,基本上 ORM 要的它都有,包括一级、二级缓存等,且屏蔽底层数据库,提高了程序的可移植行。但由于它封装的太好了,使得我们无法精细化的控制执行的 SQL。
在国外几乎都用 Hibernate ,在国内大家都用 Mybaits。
没有绝对的好坏,只有合适与不合适。
JPA
JPA(Java Persistence API)规范。
它的提出其实是为了规范,整合市面上的 ORM 框架,像 Hibernate 就符合 JPA 的规范。
不过规范仅仅只是规范,每个具体的 ORM 实现或多或少会有点修改,因此 Spring 搞了 Spring Data JPA,实现了 JPA 规范,且适配了底层各种 ORM 框架,你可以认为 Spring Data JPA 是一个胶水层。
这样我们用 Spring Data JPA 的话就在底层切换各种实现 JPA 规范的 ORM 框架。
Mybatis
Mybatis 相对于 Hibernate 称为半 ORM 框架,因为 Hibernate 不需要写 SQL ,而 Mybatis 需要写 SQL。
也因为这点 Mybatis 更加的灵活且轻量。
能针对 SQL 进行优化,非常灵活地根据条件动态拼接 SQL 等,极端情况下性能占优。
不过也因为这点 Mybatis 和底层的数据库是强绑的,如果更换底层数据库, 所有 SQL 需要重新过一遍。
比如我之前本地开发是 MySQL,后来客户特殊情况不用 saas,需要在他们那边部署一套,他们用的是 oracle,所以改咯。
具体选择 Hibernate 还是 Mybatis ,是看情况的。
比方一些项目很简单, QPS 又不高,快速解决战斗就选 Hibernate ,无脑上就完了。
而一些核心服务,QPS很高,需要对 SQL 进行精细化定制,那就 Mybatis ,就是追求极致用 Mybatis 。
#{}和${}的区别
#{} 是参数占位符,在处理的时候会与预编译将这个占位符替换为 ?,可以有效的防止 sql 注入。
${} 是变量占位符,字符串替换,直接替换文本,有注入的风险,比如传入 ‘ or 1=1’,这样的玩意。
而 #{} 是预编译,sql 的关键字在参数替换之前,已经解析了,无法再解析 ‘ or 1=1’ 这样的操作。
mybatis 的插件是如何实现的?
想要实现一个插件,就要实现 mybatis 提供的 Interceptor 接口。
Interceptor 上的 @Signature 注解表明拦截的目标方法,具体参数有 type、method、args。
例如:
@Signature(type = StatementHandler.class, method = "query", args = {Statement.class, ResultHandler.class}
我们都知道 mybatis 底层是利用 Executor 类来执行 sql 的,再具体点会有 StatementHandler、ParameterHandler、ResultSetHandler 这三个 handler。
StatementHandler 执行 sql,ParameterHandler 设置参数,由 statement 对象将 sql 和实参传递给数据库执行,再由 ResultSetHandler 封装返回的结果,所以在这几道工序之间做拦截,就能实现我们切入的功能,也就是插件。
具体的做法是实现 Interceptor ,表明要拦截的方法,填充你要切入的逻辑,然后将 Interceptor 注册到 mybatis 的配置文件(mybatis-config.xml)中。
mybatis 加载时会解析文件,得到一堆 Interceptor 组成 InterceptorChain 并保存着。
然后在创建 Executor、ParameterHandler、StatementHandler、ResultSetHandler 这几个类的对象时,就会从 InterceptorChain 得到相应的 Interceptor 通过 jdk 动态代理得到代理对象,如果没有合适的 Interceptor 则会返回原对象。
就这样,插件的逻辑就被织入了。
mybatis 如何实现数据库类型和Java类型的转换的
主要是利用 TypeHandler 这个类型转换器。
mybait 内置了很多默认的 TypeHandler 实现:
 这些 TypeHandler 会被注册到 TypeHandlerRegistry 中,实际底层就是用了很多 map 来存储类型和 TypeHandler 的对应关系:
这些 TypeHandler 会被注册到 TypeHandlerRegistry 中,实际底层就是用了很多 map 来存储类型和 TypeHandler 的对应关系:
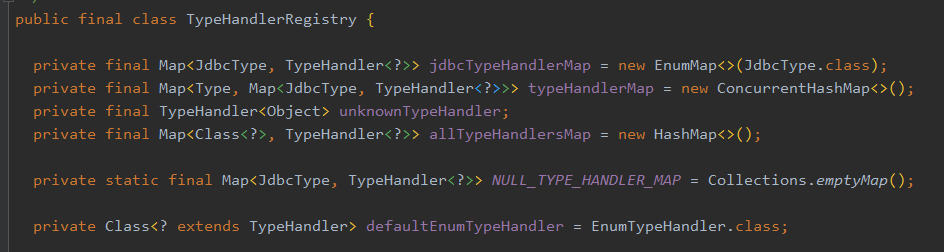
比如通过 JdbcType 找 TypeHandler ,通过 JavaType 找 TypeHandler 。
然后 TypeHandler 里面会实现类型的转化,我们拿 DateTypeHandler 来举例,很简单的:

所以,如果我们要自定义类型转换器实现 TypeHandler 接口的这几个方法即可。
在 mybatis 加载的时候,就会把这些 TypeHandler 实现类注册了,然后有对应的类型转化的时候,就会调用对应的方法进行转化。
mybatis 的数据源工厂
mybatis 提供了 DataSourceFactory 接口,具体有两个实现:
-
UnpooledDataSourceFactory
-
PooledDataSourceFactory
从名字我们就能看出一个是创建非池化的数据源、一个是池化的。
工厂创建的数据源分别是:
-
UnpooledDataSource
-
PooledDataSource
我们都知道 mybatis 其实是基于 JDBC 的,所以实际通过数据源获取连接是依靠 JDBC 的能力。
我们先来看下 UnpooledDataSource,当你从中想要获取一个连接的话,实际会调用 doGetConnection方法:

对 JDBC 有一定了解的伙伴应该很熟悉,初始化 driver,然后通过 DriverManager 获取连接,这就是 JDBC 的功能,然后把连接配置下,设置下超时时间、是否自动提交事务,事务隔离级别。
通过调用这个方法就新建连了一条连接,所以这叫非池化,因为每次获取都是新连接。
然后调用 close 就直接把连接关闭了。
有了这个基础之后,我们再来看下 PooledDataSource 的实现。

可以看到两个关键点,一个是 pop 这个名字,一个是返回的是 proxyConnection。
pop 说明是从一个地方得到连接,且 getProxyConnection 说明得到的是一个代理连接。
知晓了这两个前提之后,我们先来简单了解下连接池的原理:
连接池会保存一定数量的数据库连接,待获取连接的时候,直接从池里面拿连接,不需要重新建连,提高响应速度,预防突发流量,用完之后归还连接到连接池中,而不是关闭连接。
接下来我们详细看看 mybatis 如何实现的:
实际上 PooledDataSource 是通过一个 PoolState 对象来管理连接:

核心就是两个 list 存储了空闲的连接和活跃的连接,其他就是一些统计数据了。
然后我们可以看到,list 里面存储的是 pooledConnectiton,这玩意实现了代理逻辑,且保存了真正的 Connection 和代理的 Connection :
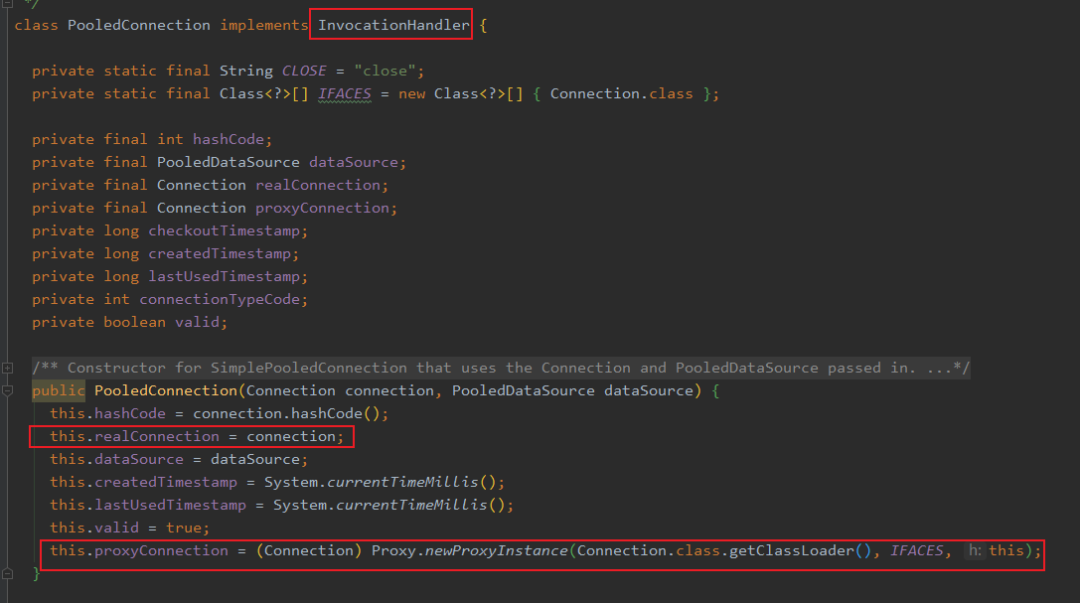
而这个代理其实只是拦截了 CLOSE 方法,也就是连接关闭的方法,让它只是归还到连接池中,而不是真正的关闭。
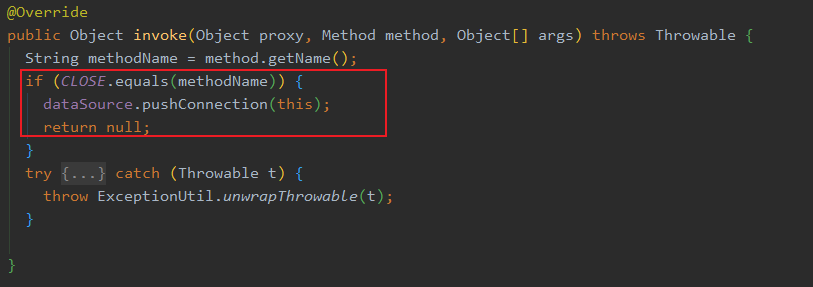
现在我们回到之前提到的 popConnection 逻辑,我用语言总结下:
-
利用 PoolState 加锁,同步执行以下流程
-
判断空闲连接列表是否有空闲连接,如果有则获得这个连接。
-
如果没有空闲连接,则看看活跃的连接是否超过限定值,不超过则通过 JDBC 获取新的连接,再由 PooledConnection 封装,获得这个连接
-
如果活跃连接超过最大限定值,则获得最老的连接(PooledConnection ),看看连接是否超时,如果超时则进行一些统计,把上面一些未提交的事务进行回滚,然后获得底层 JDBC 的连接,再新建 PooledConnection 封装这个底层连接,并把之前老连接PooledConnection 对象设置为无效
-
如果没有超时连接,则 wait 等待,默认等待 20 s。
看到这里肯定有同学会对 PooledConnection 的结构有点疑惑,这玩意除了拦截 close 方法还有什么用了?
PooledConnection 里面有个关键的 vaild 属性,这个很有用处,因为归还连接到连接池之后,不能保证外面是否持有连接的引用,所以 PooledConnection 里加了个 valid 属性,在归还的之后把代理连接置为无效,这样即使外面有这个引用,也无法使用这个连接。
所以上面才会有把已经超时的 PooledConnection 代理的底层的 JDBC 连接拿出来,然后新建一个 PooledConnection 再封装底层 JDBC 连接的操作,因为老的 PooledConnection 已经被设为无效啦。
我们再看看归还连接的流程 pushConnection,同样我还是用语言总结下:
-
poolstate 加锁
-
直接从连接活跃链表里面移除当前的连接
-
判断连接是否有效(vaild) ,无效则记录下 badConnectionCount 数量,直接返回不做其他处理
-
有效则判断连接空闲列表数量是否够了,不够则判断当前连接是否有未提交事务,有的话回滚,然后新建 PooledConnection 封装当前 PooledConnection 底层的 JDBC 连接,并加入连接空闲列表中,并把当前的 PooledConnection 置为无效,并唤醒等待的连接的线程。
-
如果连接空闲列表数量数量够了,同样则判断当前连接是否有未提交事务,有的话回滚,然后直接关闭底层 JDBC 的连接,,并把当前的 PooledConnection 置为无效。
好了,获取和归还连接的逻辑就如上所示,如果想看源码的话,代码在 PooledDataSource#popConnection 和 PooledDataSource#pushConnection 里,自己去翻阅吧~
这么看下来后,想来你对连接池的设计已经心知肚明了吧~
说说 MyBatis 的缓存机制
一级缓存默认开启,二级缓存默认关闭,可以为每个 namespace单独设置二级缓存,也可通过在多个 namespace 中共享一个二级缓存。
一级缓存是会话级缓存。即创建一个 SqlSession 对象就是一个会话,一次会话可能会执行多次相同的查询,这样缓存了之后就能重复利用查询结果,提高性能,不过 commit、rollback、update 都会清除缓存。
不过要注意,不同 SqlSession 之间的修改不会影响双方,比如 SqlSession1 读了数据 A, SqlSession2 将数据改为 B,此时 SqlSession1 再读还是得到 A ,这就出现了脏数据的问题。
所以,如果是多 SqlSession 或者分布式环境下,就可能有脏数据的情况发生。
二级缓存是命名空间级别的共享的,二级缓存只有在事务提交的时候,才会真正添加到底层的 cache 对象中,这样防止出现脏读的情况。
但是二级缓存也会有脏数据的情况,比如多个命名空间进行多表查询,各命名空间之间数据是不共享的,所以存在脏数据的情况,这时候如果利用共享 cache 就能解决。
开启二级缓存之后,会先从二级缓存查找,找不到再去一级缓存查找,找不到再去数据库查询。
二级缓存主要是利用 CachingExecutor 这个装饰器拦了一道,来看下 CachingExecutor#query 方法:
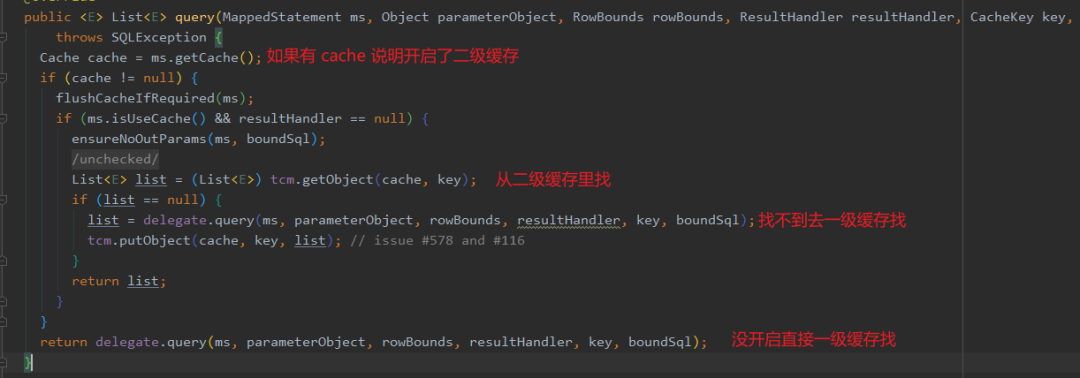
而 MyBatis 的缓存本质上就是在本地利用 map 来存储数据。
基础实现类是 PerpetualCache ,并且使用了装饰器模式,提供了各种各样的 cache 进行功能的扩展,比如:
像 BlockingCache 可以提供阻塞,FifoCache、LruCache 等等。
好了,原理大致就是上面这些,可以看到 mybaits 缓存还是不太安全,上面说的在分布式场景下肯定会出现脏数据。
建议生产上关闭缓存,直接通过 aop 利用 redis 等分布式缓存来实现。
--- EOF ---
郑重声明:本文版权归原作者所有,转载文章仅为传播更多信息之目的,如作者信息标记有误,请第一时间联系我们修改或删除,多谢。







