网页区块(Blocks)中表示,比特币挖掘过程实际上是在解决数学问题,但再阅读Block hashing algorithm这篇文章感觉还是不太理解没。也想尝试阅读bitcoind源代码,但阅读代码比阅读文档需要多得多的时间:)
谁可以从程序员的角度解释比特币挖掘过程(挖矿)?

最佳解释
挖掘算法如下:
-
步骤0 – 从网络中检索前一个区块的哈希(散列)。
-
第1步 – 收集被称为区块(“block”)的潜在交易清单列表。这个交易清单来自peer-to-peer比特币网络。
-
第2步 – 计算一个潜在交易块和一个随机数的哈希(散列)值。
-
第3步 – 如果哈希(散列)值超过当前设定的难度级别,则已开采该块。如果不是,则从步骤1重新开始。对来自步骤1的交易清单的任何增加以及来自步骤2的随机数的变化意味着有可能在接下来的周转中满足该准则。
从程序员的角度来看,伪代码可能看起来像这样:
P := The hash of the previously mined block
B := A block of transactions
H := A hash function
D := Difficulty Level
0 Retreive P
1 Construct/Modify B
2 IF H(P, B, Some Random Number) > D END
3 GOTO 1
需要注意的是,上面的描述中可能有一些不准确的地方,但大多数情况下,这应该足够好。下面是一些更有用的补充说明:
什么是哈希(散列)?
哈希是一种将数据(字符串或者二进制数据序列)转换为一定范围内的数字的函数。哈希具有输出基本上不可预知(在给定范围内)的特性。用于比特币挖掘的特定哈希函数是将SHA256应用两次。
难度级别如何工作?
哈希函数的这种不可预测的性质意味着,输入随机数据(交易+随机数)本质上会产生一定范围内的随机数。进一步限制期望输出的范围,影响一个人在一轮中找到它的可能性。这创建了一种方式:基于算法可以在网络上运行的次数概率性地确定找到解决方案的频率。特别是,当你听到术语千兆或千赫时,这是指步骤3可以运行的次数。随着整个网络每秒哈希次数的增长,网络会自动提出困难级别,以便在大约10分钟内找到解决方案。
当一个区块被挖掘时会发生什么?
当一个区块被开采时,矿工将该区块发送给网络上的所有其他矿工,作为它找到它的证据。该块包含事务列表,找到的哈希,特定的随机数以及对前一个哈希的引用。当每个矿工接收到新开采的矿块时,它会删除该矿块内存在的所有正在开采的交易(因为它们已经在块链中得到确认),并将该块广播给其他做同样事情的矿工。传播发生得非常快。注意:该矿区的原矿商获得“矿工费”,这是对除了”coinbase”奖励之外的所有交易中未使用的硬币的奖励,其开始时为50比特币,每210,000个区块后减半(大约每隔4年)。与矿工的花费相比,比特币奖励最终会变得很小,以至于微不足道。
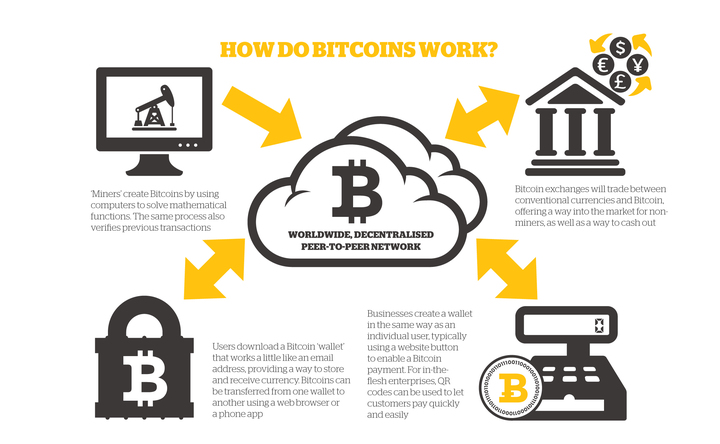
郑重声明:本文版权归原作者所有,转载文章仅为传播更多信息之目的,如作者信息标记有误,请第一时间联系我们修改或删除,多谢。








